Mode: Definition, Examples, And How To Calculate It - Explained
What is the most frequently occurring value in a dataset, and why does it matter? The mode, a fundamental concept in statistics, offers a simple yet powerful way to understand the central tendency of a data set.
Understanding the mode allows us to quickly identify the most common value within a collection of numbers, providing valuable insights in various fields, from analyzing test scores to understanding consumer preferences. This seemingly simple concept unlocks a deeper comprehension of data distribution and patterns.
| Concept | Description |
|---|---|
| Definition | The mode is the value that appears most often in a set of data. |
| Calculation | For ungrouped data, the mode can be found by observation. For grouped data, formulas can be used. |
| Types of Data | The mode can be determined for numerical and categorical data. |
| Unimodal Data | A dataset with only one mode. |
| Bimodal Data | A dataset with two modes. |
| Multimodal Data | A dataset with more than two modes. |
| Practical Applications | Used to understand popular choices, frequent occurrences, and central tendencies. |
| Examples | In the set [1, 3, 6, 6, 6, 6, 7, 7, 12, 12, 17], the mode is 6. |
| No Mode | A dataset with no repeating values has no mode. |
Reference: Khan Academy
- Transformers Corvette Stingray Collectibles More
- Life Is Good Rapper Crossword Clue Solutions Answers Find It Here
The concept of mode, while straightforward, is a cornerstone of statistical analysis. It provides a quick glimpse into data distribution, highlighting the most frequent value within a dataset. This is particularly useful in various scenarios where identifying the most common outcome or value is crucial. For instance, in a survey asking about favorite colors, the mode would represent the most popular color choice. In a set of exam scores, the mode would reveal the most frequent score achieved by the students.
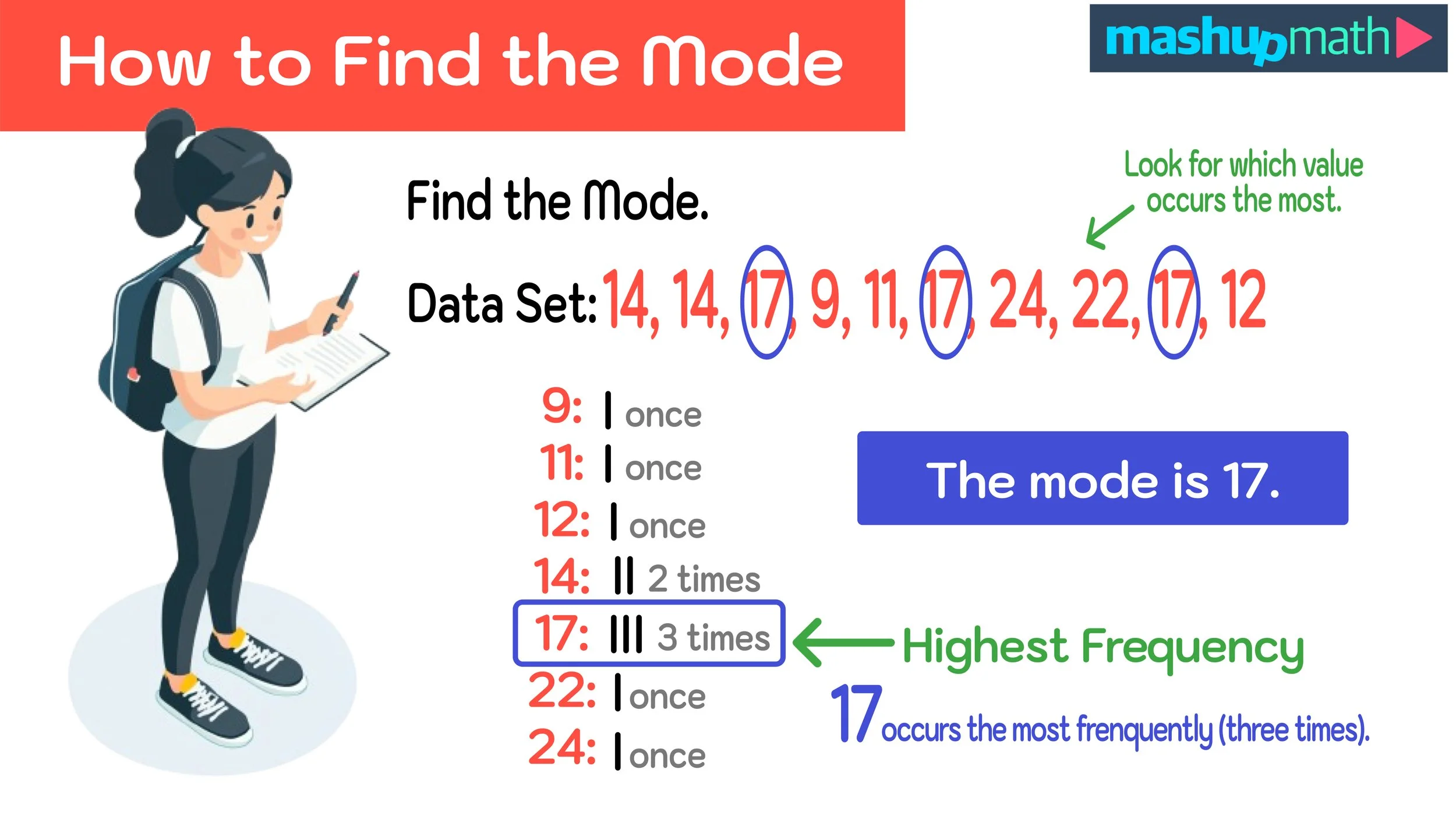
Calculating the mode is often the simplest measure of central tendency to compute. For ungrouped data such as a list of individual numbers identifying the mode involves a straightforward observation of which value appears most often. When dealing with larger datasets or data organized into frequency tables, particularly in grouped data, formulas are applied to estimate the modes value. The method of calculation differs based on the datas format, but the core principle remains consistent: identifying the most frequently occurring value.
One of the advantages of using the mode is its applicability to both numerical and categorical data. Unlike the mean (average), which requires numerical values, the mode can be used with data such as colors, brands, or types of objects. This flexibility makes the mode a versatile tool for analyzing a wide variety of datasets. It's the go-to metric when you need to find the most frequently occurring item, even when numbers are not involved.
- Traci Bingham Dead At 57 Remembering The Actress Model
- Adult Content Search What To Know Before You Browse
However, it is important to know that the mode isn't always the most suitable measure of central tendency. A dataset can have no mode if all values are unique. It can also have multiple modes, making the interpretation more complex. A dataset with two modes is called "bimodal," while one with more than two modes is "multimodal." These variations can change how the mode is interpreted and applied. Therefore, knowing the data is crucial when using the mode to draw conclusions.
The mode offers a practical advantage: it's easy to find when data is arranged in ascending order. The value that appears most often is the mode. But even when the data isnt sorted, the mode is often obvious by inspection. It's the "chill cousin" of math calculations no complicated formulas or extensive computations are needed.
Let's explore some examples to better understand the mode in action. Consider the dataset: [1, 2, 2, 3, 4, 4, 4, 5]. In this case, the mode is 4 because it appears three times, more than any other value in the dataset. In another example, if we have the dataset [1, 2, 3, 4, 5], there is no mode because each number appears only once. As mentioned earlier, the mode can also be applied to non-numerical data. For instance, if we're looking at the favorite flavors of ice cream for a group, we could have: Vanilla, Chocolate, Vanilla, Strawberry, Vanilla, Chocolate. The mode would be Vanilla, as it's the most frequently mentioned flavor.
When comparing measures of central tendency, the mean (average), median (middle value when the data is ordered), and mode each provide a different perspective on the data. The mean is sensitive to extreme values, while the median is more robust to outliers. The mode focuses on the most frequent value and is less affected by the other data points. In a normally distributed dataset (symmetrical, bell-shaped curve), the mean, median, and mode are usually all close in value. However, in skewed distributions (where data is concentrated more on one side), these measures can differ significantly, highlighting the importance of choosing the appropriate measure based on the data's characteristics and the research question.
Statistics and data play a huge part in our daily lives. Whether we're looking at the news, dealing with probability, or working through a math problem, understanding how data is organized helps us see key patterns and make informed decisions. The mode, one of the key ways to look at data, shows us which values pop up the most. Understanding data distribution and central tendency is valuable for everyone.
Understanding the mode also has practical applications that extend beyond academic exercises. Businesses use the mode to understand the sales trends of their products. Pollsters use the mode to determine the views most frequently expressed by those surveyed. Medical professionals can use the mode to analyze patient data, identifying the most common symptoms or treatment outcomes within a patient population. Understanding mode can help in everyday contexts too. It's useful when analyzing test scores to identify the most frequent score, or when looking at a list of items to find the most common.
The mode can be used across a wide variety of fields. In education, educators use the mode to understand test score trends, which helps them improve instruction. In market research, businesses use the mode to spot the most popular products, helping them to increase the effectiveness of their marketing. Medical professionals can use the mode to analyze patient data, identifying the most common symptoms or treatment outcomes within a patient population. Its also a great way to learn about a persons interests from a list of their favorite items.
For instance, consider a situation where you are trying to understand the common sizes of clothing that are bought. The mode would indicate the most frequently purchased size, helping retailers to manage inventory efficiently. In a study of customer satisfaction, the mode could identify the most frequent rating or the most common level of satisfaction reported. The ability to identify the mode is useful in many areas, helping analysts, researchers, and decision-makers extract the valuable information from a wide variety of datasets.
The importance of identifying the mode lies in its capacity to uncover the most prevalent values within a dataset, offering valuable insights for data analysis and decision-making. It is easily understood and can be used on different forms of data. Whether analyzing numerical data like exam scores or categorical data such as product preferences, the mode helps to rapidly determine the most common or most frequent occurrences.
In a situation where data isn't quantitative, the mode becomes especially valuable. For instance, in marketing research, the mode is essential in determining the most frequently selected brand or product, assisting businesses to understand customer preferences and adjust their strategies accordingly. Likewise, in studying customer satisfaction ratings, the mode highlights the most frequent ratings, giving insights into customer perceptions of products or services.
By identifying the mode, we can easily spot the most common outcome, which can be very beneficial in a wide range of cases. It enables swift assessment of central trends without getting into more complex computations, making it an effective way to get valuable insights on a wide range of data. It can also be used with the mean and median, offering a thorough picture of the information being examined.
The mean, median, and mode are the key ways of looking at central tendencies in statistics. They show us the average, middle, and most common values in a dataset. These values help us in lots of areas, such as studying the average pay in an organization or the most common age in a group. The mode is different since it focuses on the value appearing most often. It is especially useful when we want to know the most popular product or the most frequent score.
The mode has very useful applications in the real world. For instance, if you are looking at customer purchases, the mode can help you find the most popular products, which helps companies when they manage their inventory. In education, if you have test scores, the mode tells you the most common score, which helps teachers to know what to teach their students better. For the healthcare sector, by examining patient symptoms, the mode can pinpoint the most common ones.
In conclusion, the mode is an essential tool for data analysis that gives us a quick understanding of the central tendencies within a dataset. With its flexibility, ease of computation, and wide applicability, the mode remains a cornerstone for understanding and interpreting data. When used properly, the mode can uncover important patterns and insights.
This article is a brief summary of the mode, how it works and its uses. It is important to note that the mode is just one part of understanding statistics, and can be combined with the median and the mean to help you understand the data.

-Step-7.jpg)
Detail Author:
- Name : Corene McDermott
- Username : hamill.leopoldo
- Email : leffler.wiley@schimmel.com
- Birthdate : 2006-08-26
- Address : 335 Gerlach Ports Jenkinsfort, OH 10084
- Phone : 813.327.2095
- Company : Schoen LLC
- Job : Continuous Mining Machine Operator
- Bio : Magnam deserunt omnis sit reprehenderit beatae. Modi qui odit facilis minus amet. Repudiandae et impedit in asperiores perferendis.
Socials
instagram:
- url : https://instagram.com/wellington_gaylord
- username : wellington_gaylord
- bio : Hic rerum soluta repellendus. Eius natus voluptas voluptas aut. At pariatur enim optio et animi.
- followers : 4567
- following : 588
linkedin:
- url : https://linkedin.com/in/gaylord1971
- username : gaylord1971
- bio : Ut sit eos odio.
- followers : 566
- following : 973
facebook:
- url : https://facebook.com/gaylordw
- username : gaylordw
- bio : Assumenda odit omnis reiciendis deserunt nam.
- followers : 3762
- following : 376

{kind=link}